
はじめに
STORES で EC サービスの SRE エンジニアをしている秋元と申します。
今回は、EC サービスでのパフォーマンス改善について書こうと思います。 特に可視化の重要性について改めて感じたので、そのあたりについて書こうと思います。
STORES の EC サービスでは、レスポンス速度の平均値や 90 パーセンタイルではそれほど遅い値ではないんですが、たまにレスポンスに時間がかかってしまうケースがありました。
よくよく見てみると、アクセスが多くなっている時などではなく、定常的に一定の数の遅いリクエストがあることがわかりました。
さらに、遅いリクエストの URL へはいつアクセスしても遅いということがわかりました。
これらを考えると、全体で見るとサービスレベルがそれほど低くなくても、特定のユーザーや特定の操作で切り出してみるとユーザーの満足度が高くないものもあることがわかり、対応を行いました。
取り組んだこと
状況の可視化
状況を把握するために、まず今回取り組もうとしている問題の可視化をすることにしました。
可視化の要件
可視化の要件としては下記を設定しました。
- 件数の多いものを優先的に対応したい
- 一定以上の処理時間がかかっているものを抽出したい
1 について、ユーザーにより多く利用されているものを優先的に対応した方がいいと考えました。
2 については、例えばレスポンスを返すのに1秒かかっている処理と10秒かかっている処理であれば10秒かかっている処理を優先的に対応すべきと思いますが、10秒かかっている処理と20秒かかっている処理であればユーザー体験としてもどちらもよくないので、どちらも対応すべきなのかなと思います。 そこで今回は、一定以上処理時間がかかっているものについては同じ優先度として扱うこととしました。
可視化の方法
Datadog の App Analytics を利用して可視化を行いました。 https://docs.datadoghq.com/ja/tracing/app_analytics/?tab=java
App Analytics を利用すると、処理時間など様々な条件でリクエストを絞って集計でき、それをメトリクスとしてダッシュボードで利用できます。 また、ダッシュボードから各アクションの該当リクエストの一覧も確認できます。そこから各リクエストのトレースも確認でき、どこの処理に時間がかかっていて何を改善すればいいのかが簡単に把握できて非常に便利です。
今回は5秒以上かかっている処理をコントローラーのアクションごとに集計したダッシュボードを作成しました。
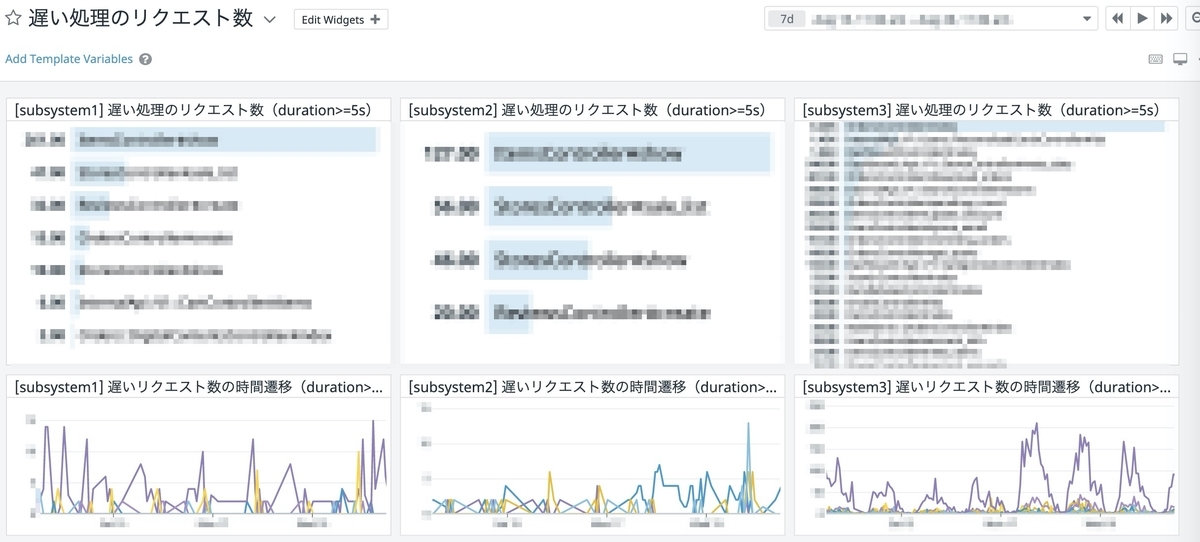
遅い処理をアクションごとに集計し、件数と時間変化を表示しています。(実際のアクション名や件数はマスクしています。)
集計結果はサブシステムごとに分けて表示しています。
可視化で気づいた問題と対応
ダッシュボードでレスポンスが遅い処理のトレースやどこで時間がかかっているかを見てみると、データベースへのインデックス追加で改善しそうなものがわりとあることがわかりました。 そこで、インデックス追加を行いパフォーマンスの改善を行いました。
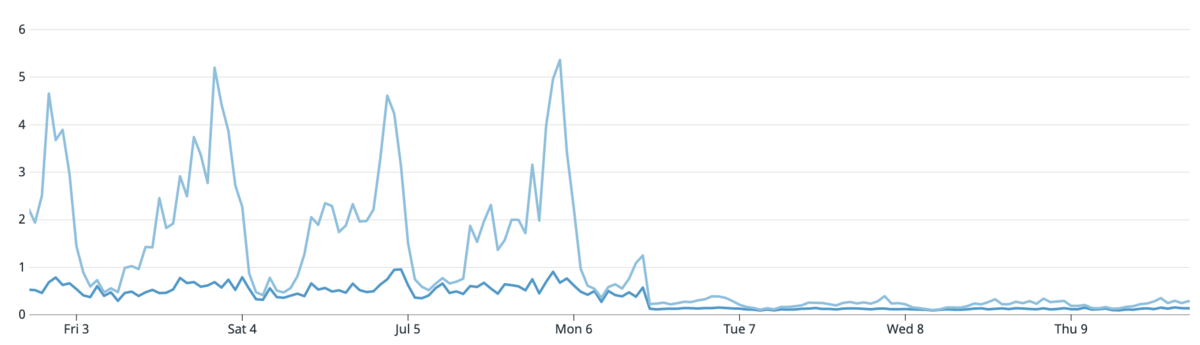
こちらは改善を行ったアクションの一例です。
青いラインが 50 パーセンタイルのレスポンス時間で水色のラインが 95 パーセンタイルのレスポンス時間です。
レスポンス時間が大きく減少しているタイミングでインデックスの追加を行いました。
インデックス追加前は 95 パーセンタイルで見るとレスポンス時間が非常に大きな値となっていましたが、インデックス追加により 95 パーセンタイルでもレスポンス時間を 1 秒以下にすることができました。
対応して思ったこと
インデックス追加のように比較的簡単に改善できるようなことがされなかった原因のひとつとして、そもそも問題が認識されていなかったことがあるのかと思います。 今回の場合だと、レスポンス時間の平均などでは大きな値となっていなかったので、なかなかわかりにくい問題だったのかと思います。
また、問題が認識されても、その重要度や対応に必要な工数がわからないと、他のタスクとの優先度がうまくつけれず対応が後回しになってしまうことも多いかと思います。 問題をわかりやすく可視化したり、簡単に調べられるようにしていくことがサービスの品質を向上させていく上で重要だということを改めて感じました。
その他の課題
今回対応は行っていないんですが、下記のような課題も見えてきました。
今回追加したインデックスの中には、ソースコード上では定義されていたんですが、データベースには反映されていないものもありました。 弊社ではメインのデータソースに MongoDB を使用しているんですが(今回インデックスを追加したのも MongoDB です)、MongoDB はスキーマレスなためデータベースマイグレーションの整備が十分に進んでいないということが背景としてはあります。 こちらについては、今後の課題として改善していきたいと考えています。
また、外部サービスへの通信がボトルネックになっているものなど、インデックスの追加だけでは解決しない問題ももちろんありました。 それらについても今後の課題として取り組んでいく必要があるかと思います。
まとめ
パフォーマンス改善を行った中で、問題の可視化や、簡単に調べられるようにしていくことがサービスの品質を向上させていく上で重要だということを改めて感じました。 まだまだ多く課題は残されていますが、引き続きユーザーの方が快適にサービスを利用していけるよう頑張っていこうと思っています。